در روز جمعه، ۱۲ ژوئن، دولت ایالات متحده کنترلهای صادراتی را بر جدیدترین مدلهای ما، کلود فیبل ۵ (Claude Fable 5) و کلود میتوس ۵ (Claude Mythos 5)، اعمال کرد. این امر مستلزم آن بود که ما دسترسی اتباع خارجی، چه در داخل و چه در خارج از ایالات متحده را محدود کنیم. از آنجا که این دستور فوراً به اجرا درآمد و ما هیچ راه قابل اعتمادی برای تأیید تابعیت در زمان واقعی نداشتیم، دسترسی به هر دو مدل را برای همه کاربران به حالت تعلیق درآوردیم.
از امروز، ۳۰ ژوئن، کنترلهای صادراتی بر فیبل ۵ و میتوس ۵ برداشته شده است.
فیبل ۵ از فردا، چهارشنبه، ۱ ژوئیه، برای کاربران جهانی در پلتفرم کلود (Claude Platform)، Claude.ai، کلود کد (Claude Code) و کلود کوورک (Claude Cowork) در دسترس خواهد بود. برای برنامههای پرو (Pro)، مکس (Max)، تیم (Team) و انتخابشده سازمانی (Enterprise),1 فیبل ۵ تا سقف ۵۰% از محدودیتهای استفاده هفتگی تا ۷ ژوئیه گنجانده خواهد شد، و پس از آن از طریق اعتبارات استفاده در دسترس خواهد بود. ما دسترسی در AWS، گوگل کلود و مایکروسافت فاندری را در اسرع وقت مجدداً فعال خواهیم کرد.
ما همچنین دسترسی به میتوس ۵ را برای مجموعهای از سازمانهای آمریکایی، به دنبال تأیید دولت ایالات متحده در ۲۶ ژوئن، بازگرداندیم. ما به هماهنگی با دولت برای گسترش دسترسی به مجموعه وسیعتری از شرکای داخلی و بینالمللی در برنامه گلسوینگ (Glasswing) ادامه میدهیم.
در ادامه این پست، جزئیات و بهروزرسانیهای بیشتری را در چهار حوزه ارائه میکنیم:
- جدول زمانی رویدادها، شامل بهروزرسانیهایی که در تدابیر امنیتی خود انجام دادیم. ما در مورد رویدادهایی که منجر به دستور کنترل صادرات شد و نحوه مقابله با آن با تدابیر امنیتی جدید بحث میکنیم.
- رویکرد کلی ما به تدابیر امنیتی. ما زمینه بیشتری را در مورد نحوه استفاده از طبقهبندیکنندههای امنیتی برای شناسایی کاربردهای سایبری بالقوه خطرناک مدلهایمان ارائه میدهیم.
- یک چارچوب صنعتی مشترک. اگرچه ما به یک راهحل سازنده دست یافتهایم، این رویدادها روشن ساختهاند که صنعت به یک روش سازگار برای ارزیابی و رفع "جیلبریکهای" احتمالی مدلهای هوش مصنوعی (تکنیکهایی که تدابیر امنیتی یک مدل را دور میزنند) نیاز دارد.2 یک استاندارد مشترک برای قضاوت در مورد شدت یک جیلبریک معین به توسعهدهندگان هوش مصنوعی کمک میکند تا یافتههای جدید را به محض بروز اولویتبندی کنند، مدلهای بسیار توانمند را با ایمنی بیشتر عرضه کنند و سطح ریسک را به طور مداوم به دولت و شرکای صنعتی اطلاع دهند. ما به همراه آمازون، مایکروسافت، گوگل و سایر شرکای گلسوینگ، توسعه چنین چارچوبی را آغاز کردهایم و آن را در ادامه تشریح میکنیم.
- همکاری عمیقتر با دولت. ما همچنین سطح همکاری خود را با دولت ایالات متحده در زمینه تستهای پیش از انتشار جدید، به اشتراکگذاری اطلاعات و همکاری تحقیقاتی تقویت میکنیم. این همکاری عمیقتر را در بخش پایانی توضیح میدهیم.
جدول زمانی و بهروزرسانیهای تدابیر امنیتی
ما فیبل ۵ و میتوس ۵ را در سهشنبه، ۹ ژوئن، منتشر کردیم. هر دو مدل از زیربنای مدل یکسانی بهره میبرند، اما فیبل ۵ با تدابیر امنیتی قویتری منتشر شد تا برای استفاده عمومی ایمنتر باشد. میتوس ۵، که تدابیر امنیتی کمتری دارد، فقط در اختیار تعداد کمی از شرکای قابل اعتماد پروژه گلسوینگ برای استفاده در امنیت سایبری دفاعی قرار گرفت.
دستور کنترل صادرات در ۱۲ ژوئن پس از آن صادر شد که دولت از گزارشی مطلع شد که در آن محققان آمازون روشی برای دور زدن تدابیر امنیتی فیبل ۵ پیدا کرده بودند: با پرامپت کردن آن به گونهای که تعدادی آسیبپذیری نرمافزاری را شناسایی کند. در یک مورد، مدل کدی را تولید کرد که نشان میداد چگونه میتوان آسیبپذیری مربوطه را مورد سوءاستفاده قرار داد. طی دو هفته گذشته، ما از نزدیک با دولت و سایر شرکا، از جمله آمازون، برای بررسی گزارش و شواهد همکاری کردیم.
آزمایشهای ما تأیید کرد که بسیاری از مدلهای کمتر توانمند – از جمله کلود اوپوس ۴.۸ (Claude Opus 4.8)، GPT-5.5، و کیمی K2.7 (Kimi K2.7) – میتوانستند همان آسیبپذیریهایی را که فیبل ۵ در گزارش شناسایی کرده بود، تشخیص دهند. در مورد نشان دادن نحوه سوءاستفاده از تنها یک آسیبپذیری، هر مدلی که ما آزمایش کردیم میتوانست همان نمونه را مانند فیبل ۵ تولید کند (از جمله کلود هایکو ۴.۵ (Claude Haiku 4.5)، سونت ۴.۶ (Sonnet 4.6)، اوپوس ۴.۶ (Opus 4.6)، اوپوس ۴.۷ (Opus 4.7)، اوپوس ۴.۸ (Opus 4.8)، GPT-5.4، GPT-5.5 و کیمی K2.7).
مهمتر اینکه، تکنیک گزارششده هیچ قابلیت سایبری منحصربهفردی در سطح میتوس را آشکار نکرد. این رفتار یک مورد مرزی برای تدابیر امنیتی فیبل ۵ را منعکس میکرد – همانطور که در ادامه توضیح خواهیم داد، برخی وظایف وجود دارند که بعید است خطرناک باشند اما با این حال به دلیل احتیاط بیش از حد توسط تدابیر امنیتی مسدود میشوند. تکنیک گزارششده امکان دسترسی به یکی از این رفتارها را فراهم میکرد، اما فقط شامل کارهای معمول امنیت سایبری دفاعی بود.
با این حال، ما به سرعت برای رفع دور زدن گزارششده اقدام کردیم. با همکاری نزدیک با دولت، یک طبقهبندیکننده امنیتی بهبود یافته را آموزش دادیم که رفتار توصیف شده در گزارش را هدف قرار داده و مسدود میکند. در صورتی که درخواستی به فیبل ۵ مسدود شود، کاربران مطلع خواهند شد و درخواست به جای آن به اوپوس ۴.۸ ارسال میشود.
طبقهبندیکننده جدید به این معنی است که تکنیک خاص توصیف شده در گزارش آمازون در بیش از ۹۹% موارد مسدود میشود. در کسر بسیار کوچکی از موارد، مدل ممکن است اطلاعاتی را ارائه دهد که به اندازه کافی جزئی نیست تا به یک مهاجم سایبری کمک کند. همانطور که در ادامه توضیح میدهیم، انتظار نمیرود تدابیر امنیتی مدل همه قابلیتهای سایبری دفاعی روتین و کمخطر را مسدود کنند – فقط مواردی که بالقوه مضر هستند. محققان مرکز استانداردها و نوآوری هوش مصنوعی (CAISI) وابسته به وزارت بازرگانی ایالات متحده، تدابیر امنیتی قبلی و جدید ما را آزمایش کرده و موافقند که آنها فوقالعاده قوی هستند.
طبقهبندیکننده جدید همچنین به قیمت پرچمگذاری بیشتر درخواستهای بیضرر در طول کارهای معمول کدنویسی و اشکالزدایی تمام میشود. مانند همه تدابیر امنیتی ما، ما به پالایش این مورد ادامه خواهیم داد تا سوءاستفاده واقعی را از درخواستهای مشروع بهتر تشخیص دهیم و خطاهای مثبت کاذب را کاهش دهیم.
رویکرد ما به تدابیر امنیتی سایبری
کلود میتوس ۵ میتواند برای یافتن و سوءاستفاده از آسیبپذیریهای نرمافزاری مؤثرتر از هر مدل دیگری – و همه به جز ماهرترین کارشناسان امنیتی انسانی – استفاده شود. این قابلیتهای سایبری خارقالعاده، آن را برای بازیگران مخربی که مایل به سوءاستفاده از آن در حملات سایبری هستند، به طور منحصربهفردی جذاب میکند.
با این حال، کلود فیبل ۵ هیچ قابلیت تهاجمی منحصربهفردی را ارائه نمیدهد. این به این دلیل است که ما آن را با قویترین تدابیر امنیتی که تا کنون برای یک مدل اعمال کردهایم، راهاندازی کردیم. در ماه قبل از راهاندازی، ما پرسنل تیمهای مختلف در انتروپیک را منتقل کردیم تا تعداد محققان و مهندسانی که روی این مشکل کار میکنند را دو برابر کنیم.
فیبل ۵ با مکانیزمهای امنیتی مختلفی راهاندازی شد که هر یک به تنهایی دفاع کاملی را ارائه نمیدهند، اما در ترکیب با یکدیگر، سوءاستفاده از مدل را بسیار دشوار میکنند (رویکردی که به آن "دفاع در عمق" گفته میشود). برخی دفاعها شامل آموزش مدل برای رد درخواستهای خطرناک است؛ برخی دیگر شامل تحلیل گذشتهنگر الگوهای سوءاستفاده میشوند.
یکی از مکانیزمهای امنیتی بسیار مهم شامل طبقهبندیکنندهها (classifiers) است – سیستمهای هوش مصنوعی خودکار کوچکتر که در طول یک تعامل، تشخیص میدهند که آیا از مدل خواسته شده است تا یک وظیفه سایبری بالقوه مضر را انجام دهد (یا خروجیهای بالقوه مضر تولید کند). وقتی این اتفاق میافتد، طبقهبندیکنندهها مدل را از پاسخگویی به درخواستها مسدود میکنند. هدف نهایی این طبقهبندیکنندهها جلوگیری از درگیر شدن مدل در رفتارهای منحصربهفرد خطرناک است.
مانند همه مکانیزمهای امنیتی، طبقهبندیکنندهها میتوانند اشتباه کنند. آنها گاهی اوقات در تشخیص محتوای بالقوه خطرناک شکست میخورند، و در برخی موارد میتوانند به طور عمدی "جیلبریک" (jailbroken) شوند: کاربران میتوانند مدل را به روشهای غیرمعمول پرامپت کنند تا طبقهبندیکنندهها را فریب دهند و مدل را وادار به تولید خروجیهای مضری کنند که سیستم باید مسدود میکرد.
بنابراین، ما عمداً طبقهبندیکنندههای امنیتی را طوری تنظیم کردیم که بر روی مجموعهای از درخواستها که میدانیم احتمالاً بیضرر هستند، فعال شوند. این رویکرد "حاشیه امنیتی" به این معنی است که یک درخواست باید به وضوح بسیار ایمن به نظر برسد تا از فعال شدن طبقهبندیکننده جلوگیری کند (به ردیف A در نمودار زیر مراجعه کنید). کاربران حاشیه امنیتی را به عنوان امتناع مدل از پاسخگویی به برخی درخواستهای منطقی و بیضرر تجربه میکنند.
برای فیبل ۵، ما این حاشیه امنیتی را بسیار بزرگتر از هر راهاندازی قبلی (ردیف B) کردیم، به این معنی که بسیاری از درخواستهای بیضرر مسدود میشدند. ما درک میکردیم که این نوع خطاهای مثبت کاذب برای کاربران ناامیدکننده خواهد بود، اما این مصالحه را به نفع در دسترس قرار دادن گسترده سایر قابلیتهای مدل انجام دادیم.
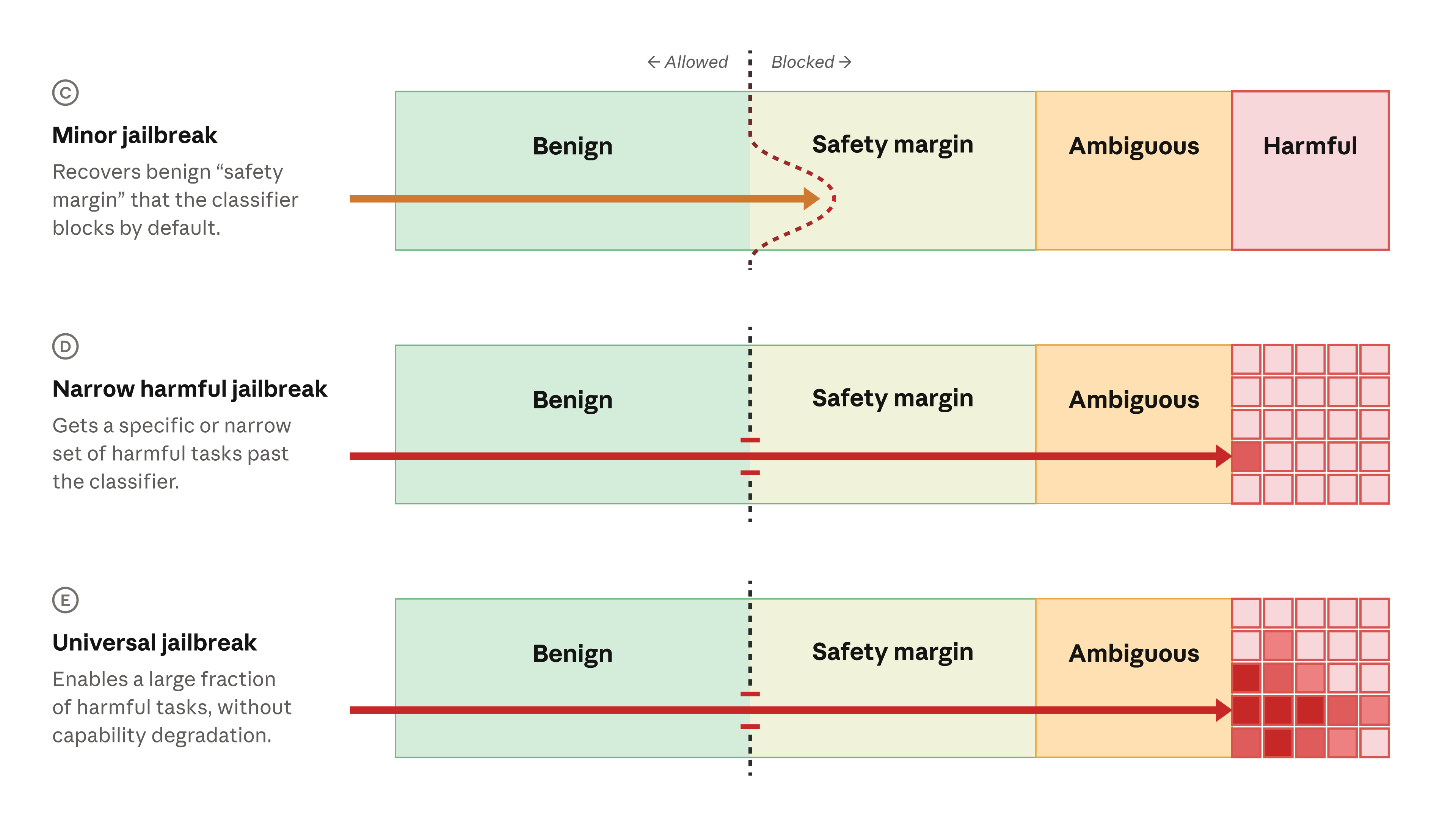
در مورد یک جیلبریک جزئی (ردیف C)، طبقهبندیکنندهها درخواست را مسدود نمیکنند، اما درخواست همچنان در حاشیه امنیتی ما قرار دارد (و بنابراین بسیار بعید است که مضر باشد). در یک جیلبریک مضر محدود (ردیف D)، پرامپت از طبقهبندیکنندهها عبور میکند و یک رفتار مضر خاص را از مدل باز میکند. در یک جیلبریک جهانی (ردیف E)، یک پرامپت یک کلاس کامل از رفتارهای مضر را باز میکند.
حاشیه امنیتی همچنین به کاهش جیلبریکها کمک میکند. بسیاری از جیلبریکها محدود هستند: آنها یک رفتار مدل بسیار خاص را باز میکنند اما نه بیشتر. در برخی موارد، یک کاربر فرضی میتواند مدل را به روشی جزئی جیلبریک کرده و به حاشیه امنیتی (یا گاهی اوقات به رفتار مبهم مضر) نفوذ کند، اما نه به رفتارهای اصلی مضر که هدف ما مسدود کردن آنهاست (ردیف C در ادامه). دیدگاه ما این است که جیلبریکهای فیبل ۵ که تا کنون گزارش شدهاند در این دسته جزئی قرار میگیرند.
جیلبریکهای جدیتر رفتارهای مضر بیشتری را باز میکنند. جیلبریکهای مضر محدود (ردیف D) میتوانند برخی رفتارهای مضر خاص را استخراج کنند. این جیلبریکها معمولاً دارای شدت کم تا متوسط هستند، زیرا محدودیت، مهاجم را محدود میکند. نگرانکنندهترین دسته، یک جیلبریک جهانی (ردیف E) است که طیف وسیعی از رفتارهای مضر را باز میکند.
همانطور که هنگام راهاندازی فیبل ۵ اشاره کردیم، احتمالاً ساخت هر مدل هوش مصنوعی کاملاً مقاوم (یعنی نفوذناپذیر) در برابر جیلبریکها غیرممکن است.3 ما انتظار داریم که برخی جیلبریکها برای مدلهای ما یافت شوند، و شدت آنها متفاوت خواهد بود: جیلبریکهای جزئی بسیاری، برخی مضر محدود، و اگرچه در زمان نگارش هیچ جیلبریک جهانی برای فیبل ۵ کشف نشده است، محققان امنیتی متخصص به بازبینی آن ادامه میدهند. ما تلاش میکنیم تا اطمینان حاصل کنیم که ما و شرکای امنیتیمان اولین کسانی خواهیم بود که جیلبریکهای اصلی را پیدا کرده و قبل از اینکه بازیگران مخرب بتوانند از آنها برای آسیب استفاده کنند، آنها را رفع کنیم.
رویکرد محتاطانه ذکر شده در بالا به این معنی است که اکثریت قریب به اتفاق جیلبریکها رفتارهای خطرناک را با موفقیت باز نخواهند کرد. طبقهبندیکنندههای ما تولید جیلبریکهای موفق را بسیار پرهزینه و با تلاش بالا میکنند، و حتی اگر یک جیلبریک موفقیتآمیز باشد، لایههای دفاعی اضافی ما کاهش دهنده بیشتری را فراهم میکنند. ما به بهروزرسانی طبقهبندیکنندههای خود ادامه خواهیم داد زیرا اطلاعات بیشتری در مورد تکنیکهای جدید جیلبریک کسب میکنیم.
چارچوب صنعتی توافقی برای جیلبریکها
در حال حاضر هیچ اجماعی در صنعت هوش مصنوعی در مورد نحوه توصیف عینی شدت یک جیلبریک هوش مصنوعی وجود ندارد. این امر هر زمان که یک تکنیک جیلبریک جدید کشف میشود، ابهام زیادی ایجاد میکند: توسعهدهندگان استاندارد توافقشدهای برای تمرکز بر کدام یافتهها با فوریت بیشتر ندارند، و دولتها نیز استاندارد توافقشدهای برای زمان اقدام ندارند.4
این مشکل در ماههای آینده حادتر خواهد شد، زیرا مدلهای بیشتری با قابلیتهای قدرتمند امنیت سایبری (و سایر قابلیتها) آموزش، ارزیابی و منتشر میشوند. یک استاندارد مشترک برای ارزیابی جیلبریکهای هوش مصنوعی به ما و سایر شرکتها کمک میکند تا مدلهای جدید را به طور ایمن راهاندازی کنیم و همچنین به کاربرانمان امکان میدهد از قابلیتهای پیشرفته آنها نهایت استفاده را ببرند.
بنابراین، ما با آمازون، مایکروسافت، گوگل و سایر شرکای گلسوینگ همکاری میکنیم تا یک چارچوب توافقی برای ارزیابی شدت جیلبریکهای هوش مصنوعی و نحوه واکنش توسعهدهندگان هوش مصنوعی به آنها تدوین کنیم. ما از سایر شرکای صنعتی و ارائهدهندگان مدل دعوت میکنیم تا در این تلاش به ما بپیوندند.
پیشنهاد فعلی ما این است که یک جیلبریک معین را بر اساس چهار معیار مختلف زیر امتیازدهی کنیم. دو مورد اول آنچه جیلبریک به مهاجم میدهد را توصیف میکنند؛ دو مورد آخر چگونگی سریع تبدیل شدن جیلبریک به یک مشکل واقعی را توصیف میکنند:
- افزایش قابلیت. جیلبریک کاربر را تا چه حد فراتر از ابزارهای موجود پیش میبرد؟ اگر ابزارهای موجود و در دسترس (از جمله سایر مدلهای هوش مصنوعی ضعیفتر) بتوانند به همان قابلیت مدل جیلبریک شده برسند، امتیاز در اینجا پایین خواهد بود؛ اگر جیلبریک قابلیتهای مدل را باز کند که میتواند حتی کارشناسان حوزه را به طور قابل توجهی تسریع کند، امتیاز بالا خواهد بود.
- گستره افزایش قابلیت. همان تکنیک جیلبریک برای چند وظیفه تهاجمی متمایز کار میکند؟ مواردی که جیلبریک فقط به مدل امکان میدهد اهداف محدودی را دنبال کند، امتیاز پایینی خواهند داشت؛ مواردی که همان تکنیک جیلبریک برای چندین هدف یا تکنیک مختلف کار میکند، امتیاز بالایی خواهند بود.
- سهولت تسلیحاتی شدن. چقدر تلاش انسانی لازم است تا جیلبریک به یک حمله تبدیل شود؟ در مواردی که جیلبریک شامل مقدار زیادی پرامپتینگ ماهرانه و تلاشهای مکرر باشد، امتیاز پایین خواهد بود؛ در مواردی که جیلبریک با یک پرامپت واحد یا در اولین یا دومین تلاش کار کند، امتیاز بالا خواهد بود.
- قابلیت کشف. به دست آوردن این تکنیک چقدر آسان است؟ اگر نیاز به دانش تخصصی داشته باشد، امتیاز پایین خواهد بود؛ اگر در حال حاضر به طور گسترده شناخته شده و آنلاین در دسترس باشد، امتیاز بالا خواهد بود.
ما پیشنهاد میکنیم از این چارچوب شدت برای کالیبره کردن واکنش خود به جیلبریکهای تازه کشف شده استفاده کنیم. برای شدیدترین دسته از جیلبریکها (به عنوان مثال، جیلبریکی که، در میان سایر ویژگیها، به طور فعال برای ایجاد تأثیر مخرب بر شبکههای برق حیاتی یا سیستمهای بانکی استفاده میشود)، بلافاصله پس از تأیید شدت، اقدامات کاهش اولیه را آغاز خواهیم کرد. ما همچنین تیمی را برای نظارت ۲۴/۷ بر کانالهای کلیدی ارسال جیلبریک ایجاد میکنیم.
هر روشی برای امتیازدهی جیلبریکها ناقص خواهد بود. با این حال، ارزش دارد که بتوان شدت تقریبی یک یافته معین را از طریق یک چارچوب مشترک انتقال داد. این یک کار در حال انجام است؛ با دریافت بازخورد از شرکای بیشتر، انتظار داریم این چارچوب به مرور زمان تکامل یابد.
ما انتظار داریم به زودی جزئیات بیشتری در مورد چارچوب پیشنهادی به اشتراک بگذاریم. در همین حال، ما یک برنامه جدید HackerOne را نیز راهاندازی میکنیم که در آن محققان امنیتی میتوانند جیلبریکهای سایبری احتمالی را که در فیبل ۵ کشف کردهاند (پس از در دسترس قرار گرفتن) برای بررسی ما ارسال کنند.
همکاری با دولت ایالات متحده در امنیت هوش مصنوعی پیشرو
طی ده هفته گذشته، انتروپیک از نزدیک با دولت ایالات متحده در توسعه رویکرد منعکس شده در فرمان اجرایی ۲ ژوئن در مورد ترویج نوآوری و امنیت هوش مصنوعی پیشرفته همکاری کرده است. تعامل ما شامل دفتر مدیر ملی سایبری، دفتر سیاست علم و فناوری، وزارت خزانهداری، وزارت بازرگانی (شامل CAISI) و آژانسهای امنیت ملی مربوطه بود.
ما متعهد به ادامه این کار هستیم، با تکیه بر تقریباً دو سال همکاریهای قبلی با شرکای دولتی ایالات متحده در زمینه آزمایش و ارزیابی پیش از استقرار. تعهدات زیر هم بازتاب آن کار قبلی و هم پیشنهادات جدید ما برای افزایش همکاری دولتی ما با نهایی شدن چارچوب فوق است:
- دسترسی و ارزیابی دولتی پیش از انتشار. برای مدلهایی که به طور اساسی مرز قابلیت را در زمینههای مرتبط با امنیت ملی پیش میبرند، ما دسترسی اولیه گستردهتری را به مدلها و تدابیر امنیتی همراه آنها به شرکای دولتی تعیینشده ارائه خواهیم داد. این شرکا سپس میتوانند ارزیابیهای قابلیت مستقل را اجرا کرده و تدابیر ما را قبل از انتشار گسترده آزمایش کنند. ما پرسنل فنی انتروپیک را برای همکاری با ارزیابهای دولتی در طول این دورههای آزمایش اختصاص خواهیم داد.
- به اشتراکگذاری سریع اطلاعات در مورد تدابیر امنیتی. هنگامی که جیلبریکهای مهم یا الگوهای سوءاستفاده شناسایی میشوند، ما به سرعت بررسی، اولویتبندی و به همتایان دولتی مناسب اطلاعرسانی خواهیم کرد. ما تدابیر امنیتی جدیدی را که در پاسخ به آنها میسازیم به اشتراک خواهیم گذاشت تا بتوانند به طور مستقل آزمایش شوند. ما همچنین گزارشهای اطلاعات تهدید خود را قبل از انتشار به شرکای دولتی ارائه خواهیم داد و در مرکز تبادل اطلاعات آسیبپذیری سایبری بینسازمانی که طبق بخش 2(d) فرمان اجرایی 2 ژوئن تأسیس شده است، شرکت خواهیم کرد.
- منابع اختصاصی برای تحقیقات مشترک. ما به طور قابل توجهی کار مشترک با شرکای دولتی در زمینه امنیت هوش مصنوعی را افزایش میدهیم. ما تیمهای اختصاصی انتروپیک را برای کار بر روی اولویتهای مشترک دولتی تشکیل خواهیم داد، تخصیص محاسباتی قابل توجهی را برای حمایت از آزمایش و تحقیقات دولتی فراهم خواهیم کرد، و تخصص امنیتی و "red-teaming" خود را برای کمک به پیشبرد وضعیت هنر در ارزیابی هوش مصنوعی در دسترس قرار خواهیم داد.
- یک استاندارد صنعتی مشترک. ما با دولت و با همتایان صنعتی در جهت یک استاندارد امنیتی و ارزیابی مشترک و داوطلبانه برای ارائهدهندگان مدلهای پیشرو کار خواهیم کرد. ما ارزیابیها، ابزارها و بهترین شیوههایی را که دولت میتواند در سراسر حوزه اعمال کند، کمک خواهیم کرد.
امید ما این است که این همکاری، همراه با چارچوب صنعتی توافقی پیشنهادی ما، مبنایی برای قوانین سیستماتیک برای کل صنعت – و حتی آغازگر الگویی برای هماهنگی جهانی مؤثر در مورد خطرات و مزایای هوش مصنوعی – باشد.
این قوانین باید در مقررات قوی تدوین شده و به طور یکسان در میان توسعهدهندگان مدلهای پیشرو اعمال شوند. دخالت دولت در انتشار هوش مصنوعی مستلزم یک فرآیند پایدار و شفاف است که به مدافعان سایبری و سایرین اطمینانی را که در مورد دسترسی به مدلهای قدرتمند نیاز دارند، میدهد.
ما مشتاقانه منتظر تعمیق همکاری دولتی خود به روشهای ذکر شده در بالا هستیم. ما همچنین از کاربران خود به خاطر صبر و شکیبایی در طول این اختلال، و از محققان و شرکای صنعتی که در کنار ما برای در دسترس قرار دادن مجدد فیبل ۵ و میتوس ۵ تلاش کردند، سپاسگزاریم.