
در فوریهٔ امسال، تیموتی پوآزو، بومشناس، زمانی که بررسیهای همتای یک دستنوشته را که برای انتشار ارسال کرده بود، خواند، شگفتزده شد. به نظر میرسید یکی از گزارشهای داوری با استفاده از هوش مصنوعی (AI) نوشته شده باشد، یا شاید بهطور کامل توسط آن نوشته شده باشد. این گزارش شامل این جملهٔ گویا بود: «این نسخهٔ اصلاحشدهٔ بررسی شما با وضوح و ساختار بهبودیافته است»، که نشانهٔ قویای بود که متن توسط مدلهای زبانی بزرگ (LLM) تولید شده است.
پوآزو هنوز سردبیر مجله را از سوءظن خود آگاه نکرده است؛ او درخواست کرد که نام مجلهٔ مربوطه - که استفاده از LLMها را در بررسیهای همتا ممنوع کرده است - در این مقاله فاش نشود.
اما در یک پست وبلاگی دربارهٔ این حادثه، او بهشدت علیه بررسی همتای خودکار استدلال کرد. پوآزو، که در دانشگاه مونترال در کانادا کار میکند، نوشت: «من یک دستنوشته را به امید دریافت نظرات از همکارانم برای بررسی ارسال میکنم. اگر این فرض برآورده نشود، کل قرارداد اجتماعی بررسی همتا از بین میرود.»
سیستمهای هوش مصنوعی در حال حاضر در حال تغییر بررسی همتا هستند - گاهی با تشویق ناشران و گاهی در نقض قوانین آنها. ناشران و محققان به طور یکسان در حال آزمایش محصولات هوش مصنوعی برای علامتگذاری خطاها در متن، دادهها، کد و منابع دستنوشتهها، هدایت داوران به سمت بازخورد سازندهتر و اصلاح نثر آنها هستند. برخی از وبسایتهای جدید حتی بررسیهای کاملاً ایجادشده توسط هوش مصنوعی را با یک کلیک ارائه میدهند.
اما با این نوآوریها، نگرانیهایی نیز به وجود میآید. اگرچه محصولات هوش مصنوعی امروزی در نقش دستیار قرار دارند، اما هوش مصنوعی ممکن است در نهایت بر فرآیند بررسی همتا تسلط پیدا کند و نقش داور انسانی کاهش یابد یا به طور کلی حذف شود. برخی از علاقهمندان، خودکارسازی بررسی همتا را امری اجتنابناپذیر میدانند - اما بسیاری از محققان، مانند پوآزو، و همچنین ناشران مجلات، آن را یک فاجعه میدانند.
ویرایشگر دیگر من هوش مصنوعی است
حتی قبل از ظهور ChatGPT و سایر ابزارهای هوش مصنوعی مبتنی بر LLM، ناشران به مدت بیش از نیم دهه از انواع برنامههای هوش مصنوعی برای تسهیل فرآیند بررسی همتا استفاده میکردند - از جمله برای کارهایی مانند بررسی آمار، خلاصهسازی یافتهها و تسهیل انتخاب داوران همتا. اما ظهور LLMها، که از نگارش روان انسانی تقلید میکنند، بازی را تغییر داده است.
در یک نظرسنجی از نزدیک به ۵۰۰۰ محقق، حدود ۱۹٪ گفتند که قبلاً استفاده از LLMها را برای «افزایش سرعت و سهولت» بررسی خود امتحان کردهاند. اما این نظرسنجی، توسط ناشر وایلی، مستقر در هوبوکن، نیوجرسی، تعادل بین استفاده از LLMها برای ویرایش نثر و تکیه بر هوش مصنوعی برای تولید بررسی را بررسی نکرد.
یک مطالعه1 در مورد گزارشهای بررسی همتا برای مقالاتی که در کنفرانسهای هوش مصنوعی در سالهای ۲۰۲۳ و ۲۰۲۴ ارائه شدهاند، نشان داد که بین ۷٪ و ۱۷٪ از این گزارشها حاوی نشانههایی هستند که بهطور قابلتوجهی توسط LLMها تغییر یافتهاند - به این معنی که تغییراتی فراتر از بررسی املایی یا بهروزرسانیهای جزئی در متن ایجاد شده است.
بسیاری از تأمینکنندگان مالی و ناشران در حال حاضر داوران کمکهای مالی یا مقالات را از استفاده از هوش مصنوعی منع میکنند و به نگرانی در مورد درز اطلاعات محرمانه در صورت بارگذاری مطالب در وبسایتهای چتبات توسط محققان اشاره میکنند. اما سباستین پورسدام مان، از دانشگاه کپنهاگ، که کاربردهای عملی و اخلاق استفاده از هوش مصنوعی مولد در تحقیقات را مطالعه میکند، میگوید که اگر محققان LLMهای آفلاین را در رایانههای خود میزبانی کنند، دادهها به فضای ابری بازگردانده نمیشوند.
دریتون گرودا، محقق رفتار سازمانی در دانشگاه کاتولیک پرتغال در لیسبون، در ستون مشاغل Nature نوشت: استفاده از LLMهای آفلاین برای بازنویسی یادداشتها میتواند فرآیند نوشتن بررسیها را تسریع و واضحتر کند، تا زمانی که LLMها «یک بررسی کامل را از طرف شما انجام ندهند».
اما کارل برگستروم، زیستشناس تکاملی در دانشگاه واشنگتن در سیاتل، در پاسخ میگوید: «یادداشتبرداری سطحی و استفاده از LLM برای ترکیب آنها بسیار کمتر از نوشتن یک بررسی همتای کافی است». اگر داوران شروع به تکیه بر هوش مصنوعی کنند تا بتوانند بیشتر فرآیند نوشتن بررسیها را نادیده بگیرند، خطر ارائهٔ تحلیلهای سطحی را به جان میخرند. برگستروم میگوید: «نوشتن، فکر کردن است.»
پورسدام مان میگوید که LLMها قطعاً میتوانند سبک برخی از داوران را بهبود بخشند: این تعجبآور نیست، با توجه به اینکه برخی از بررسیهای همتا سرسری یا ضعیف نوشته شدهاند. با این حال، خروجی LLM تقریباً همیشه حاوی خطا است، زیرا این ابزارها با تولید متنی کار میکنند که بر اساس دادههای آموزشی و ورودیهایشان از نظر آماری محتمل به نظر میرسد - اگرچه محققان در حال یافتن راههایی برای کاهش نرخ خطا هستند.
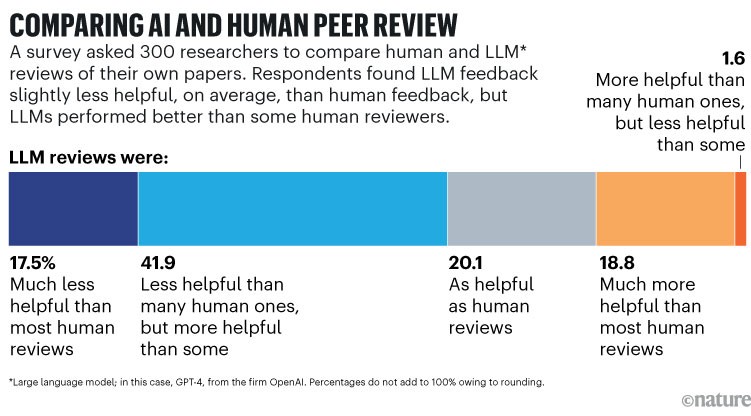
بر اساس مطالعهای که بیش از ۳۰۰ زیستشناس محاسباتی و محقق هوش مصنوعی ایالات متحده را با بررسیهایی از مقالات خودشان ارائه کرد - برخی توسط داوران انسانی و برخی دیگر توسط GPT-4، یکی از LLMهای پیشرو در آن زمان2 - در بسیاری از موارد، تفاوت بین انسان و LLM چندان زیاد نیست. حدود ۴۰٪ از پاسخدهندگان گفتند که هوش مصنوعی یا مفیدتر از بررسیهای انسانی بوده است یا به همان اندازه مفید بوده است؛ و ۴۲٪ دیگر گفتند که هوش مصنوعی کمتر از بسیاری از بررسیها مفید بوده است، اما مفیدتر از برخی از آنها بوده است.
هوش مصنوعی که فراتر از ویرایش میرود
تیمی که پشت مطالعه مقایسهٔ بررسیهای هوش مصنوعی و انسانی قرار دارد، به رهبری جیمز زو، زیستشناس محاسباتی در دانشگاه استنفورد، کالیفرنیا، اکنون در حال توسعهٔ یک «عامل بازخورد» برای داوران است. این عامل، گزارشهای بررسی انسانی را در برابر چکلیستی از مسائل رایج - مانند بازخورد مبهم یا نامناسب - ارزیابی میکند و به نوبهٔ خود، پیشنهادهایی را در مورد چگونگی بهبود نظرات خود به داوران ارائه میدهد.
در یک نمایشگاه نوآوری ناشران در لندن در دسامبر گذشته، بسیاری از توسعهدهندگان هوش مصنوعی برای ارائهٔ محصولاتی برای بهبود بررسی همتا صف کشیدند که فراتر از ویرایش صرف انجام میدهند. یکی از این ابزارها، به نام Eliza، که سال گذشته توسط شرکت World Brain Scholar (WBS) در آمستردام، هلند، راهاندازی شد، پیشنهادهایی را برای بهبود بازخورد داوران ارائه میدهد، منابع مرتبط را توصیه میکند و بررسیهای نوشتهشده به زبانهای دیگر را به انگلیسی ترجمه میکند. زگر کارسن، بنیانگذار WBS، میگوید که این ابزار قرار نیست جایگزین داوران همتای انسانی شود. او میگوید: «این ابزار فقط آنچه را که داور همتا نوشته است، تجزیهوتحلیل میکند.»
ابزار مشابهی Review Assistant است که توسط شرکت چندملیتی خدمات انتشاراتی Enago و Charlesworth توسعه یافته است. در ابتدا، این ابزار از یک سیستم LLM برای پاسخ دادن به پرسشهای ساختاریافته در مورد یک دستنوشته استفاده میکرد که داوران میتوانستند آنها را بررسی یا تأیید کنند. اما پس از صحبت با ناشران، توسعهدهندگان یک حالت «انسان اول» را اضافه کردند که در آن داوران به پرسشها پاسخ میدهند و سپس یک ابزار هوش مصنوعی به پاسخهای آنها نگاه میکند. مری میسکین، مدیر عملیات جهانی در Charlesworth، که در هادرسفیلد، انگلستان مستقر است، میگوید این ابزار میتواند «از داوران حمایت کند تا آنچه را که ممکن است بهطور نامشروع انجام دهند، به روشی مشروع انجام دهند.»
رویکرد دیگری در هوش مصنوعی، هدفش رهایی داوران از بخشهای پر زحمت بررسی همتا است. یک شرکت نوپا به نام Grounded AI، در استیونج، انگلستان، ابزاری به نام Veracity را توسعه داده است که بررسی میکند آیا مقالات ذکرشده در دستنوشتهها وجود دارند یا خیر، و سپس - با استفاده از یک LLM - تجزیهوتحلیل میکند که آیا کار ذکرشده با ادعاهای نویسنده مطابقت دارد یا خیر. نیک مورلی، یکی از بنیانگذاران این شرکت، میگوید این ابزار مانند «گردش کاری است که یک بررسیکنندهٔ حقایق انسانی با انگیزه و دقیق، در صورت داشتن تمام وقت دنیا، انجام میدهد.»
و مجموعهای از تلاشها برای بهکارگیری ابزارهای کمکی LLM در مقالات موجود انجام شده است - از نرمافزار برای شناسایی تکثیر تصویر گرفته تا برنامههای بررسی آمار. اما محققان ابراز نگرانی کردهاند که LLMها میتوانند غیرقابلاعتماد باشند و برخی از خطاهای ظاهری میتوانند مثبت کاذب باشند.
یکی از ابزارهای بررسی هوش مصنوعی که در حال حاضر در حال آزمایش با ناشران است، Alchemist Review است که توسط Grounded AI و شرکتی به نام Hum در شارلوتزویل، ویرجینیا، توسعه یافته است. سازندگان این نرمافزار میگویند که میتواند یافتهها و روشهای اصلی را خلاصه کند و نوآوری تحقیق را ارزیابی کند، و همچنین استنادها را تأیید کند. آنها همچنین میگویند که داوران میتوانند از این ابزار در یک محیط امن استفاده کنند که از محرمانه بودن دستنوشتهها و مالکیت معنوی نویسندگان محافظت میکند.
آن مایکل، مدیر ارشد تحول در AIP Publishing، بازوی انتشاراتی مؤسسهٔ فیزیک آمریکا، مستقر در ملويل، نیویورک، میگوید که در حال آزمایش نسخه ای از این نرمافزار در دو مجله است. ویراستاران مجله یک نمونه اولیه از این ابزار را آزمایش خواهند کرد و به تشخیص خود، به برخی از داوران همتا اجازه میدهند آن را امتحان کنند. با این حال، ناشر توانایی این ابزار در قضاوت در مورد نوآوری را آزمایش نخواهد کرد، زیرا نظرسنجیهای داخلی نشان داد که ویراستاران این ویژگی را به اندازه سایر ویژگیها مفید نمیدانند، مایکل میگوید. او با تأکید بر اینکه این ابزار قبل از بررسی انسانی استفاده میشود، نه برای جایگزینی آن، میگوید: «ما در تلاش هستیم تا یاد بگیریم که چگونه به طور مسئولانه هوش مصنوعی را در بررسی همتا به کار ببریم.»
سایر ناشران نیز به Nature گفتند که در حال بررسی توسعه ابزارهای هوش مصنوعی داخلی برای بررسی همتا هستند، اما دقیقاً نگفتند روی چه چیزی کار میکنند. سخنگوی وایلی گفت، برای مثال، وایلی «در حال بررسی موارد استفادهٔ بالقوهٔ مختلف برای هوش مصنوعی برای تقویت بررسی همتا، از جمله در سطوح ویراستار و داور است.»
یک مطالعهٔ دسامبر ۲۰۲۴ از دستورالعملهای مجلات برتر پزشکی3 نشان داد که در میان ناشران بزرگ، الزویر در حال حاضر داوران را از استفاده از هوش مصنوعی مولد یا بررسی با کمک هوش مصنوعی منع میکند، در حالی که وایلی و Springer Nature اجازهٔ «استفاده محدود» را میدهند. هم Springer Nature و هم وایلی مستلزم افشای هرگونه استفاده از هوش مصنوعی برای حمایت از بررسی هستند و بارگذاری آنلاین دستنوشتهها را ممنوع میکنند. (تیم خبری Nature از نظر تحریری مستقل از ناشر خود است.) این مطالعه خاطرنشان کرد که ۵۹٪ از ۷۸ مجلهٔ برتر پزشکی که در این مورد راهنمایی داشتند، استفاده از هوش مصنوعی در بررسی همتا را ممنوع کردهاند. بقیه آن را با الزامات مختلف مجاز میدانند.
بررسی مبتنی بر هوش مصنوعی؟
رادیکالترین کاربردهای هوش مصنوعی در بررسی همتا، ابزارهایی هستند که مستقیماً بررسیهای خودکار دستنوشتهها را ارائه میدهند. یک نمونه Paper-Wizard است که هنگام بارگذاری یک مقاله، بررسیهای چندصفحهای کاملی را ایجاد میکند و جنبههای دقیقی از طرحهای روششناختی، مانند دقت آماری را بررسی میکند. شین ارهارت، متخصص علوم اعصاب شناختی در بریزبن، استرالیا، که یکی از سازندگان آن است، میگوید که این یک محصول «پیش از بررسی همتا» است که برای کمک به نویسندگان در کار خودشان در نظر گرفته شده است.
منابع
- Liang, W. et al. Proc. 41st Int. Conf. Mach. Learn. 235, 29575–29620 (2024).
- Liang, W. et al. N. Engl. J. Med. AI https://doi.org/10.1056/AIoa2400196 (2024).
- Li, Z.-Q. et al. JAMA Netw Open. 7, e2448609 (2024).
- Oviedo-García, M. Á. Scientometrics 129, 5805–5813 (2024).
- Bauchner, H. & Rivara, F. P. Health Aff. Sch. 2, qxae058 (2024).